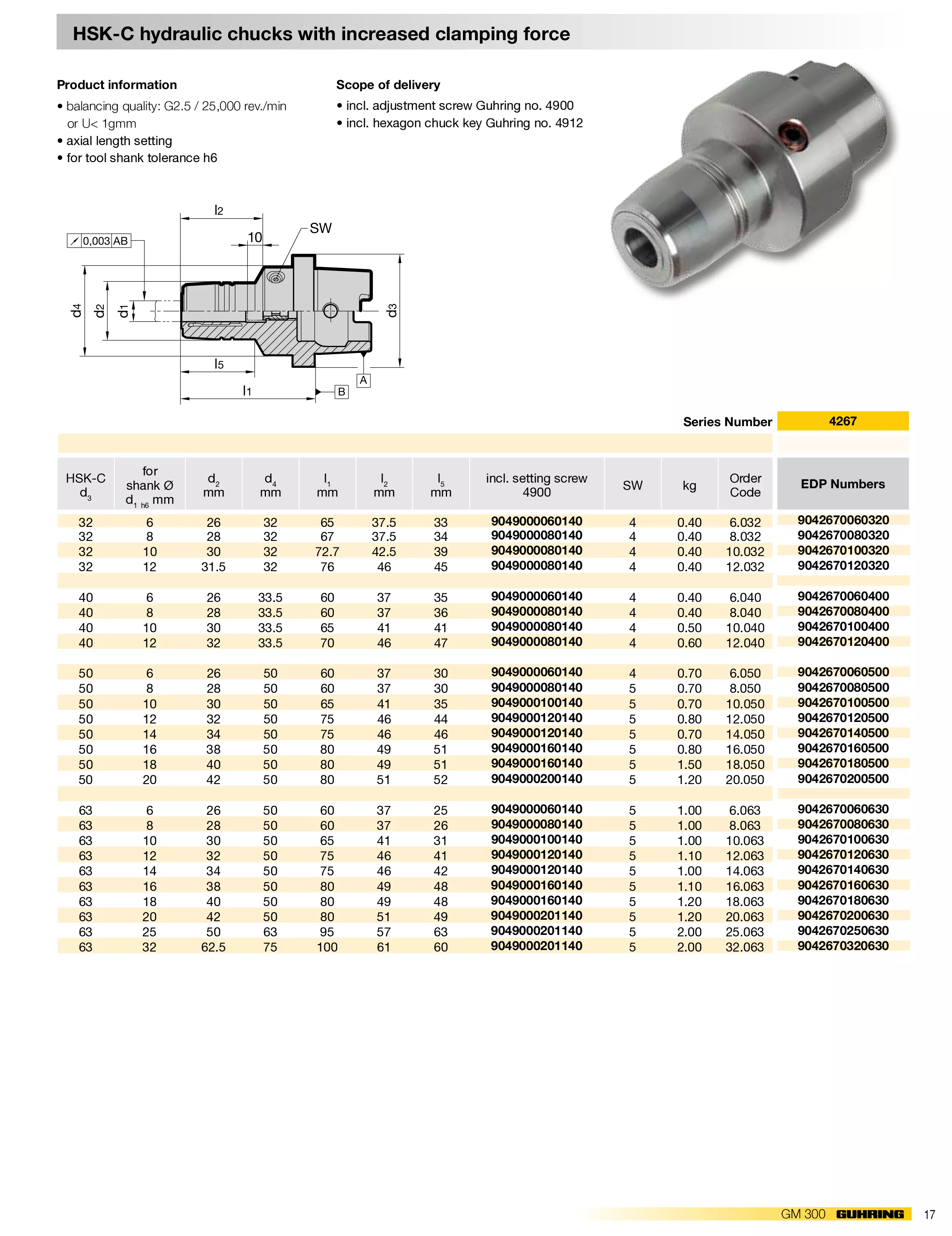
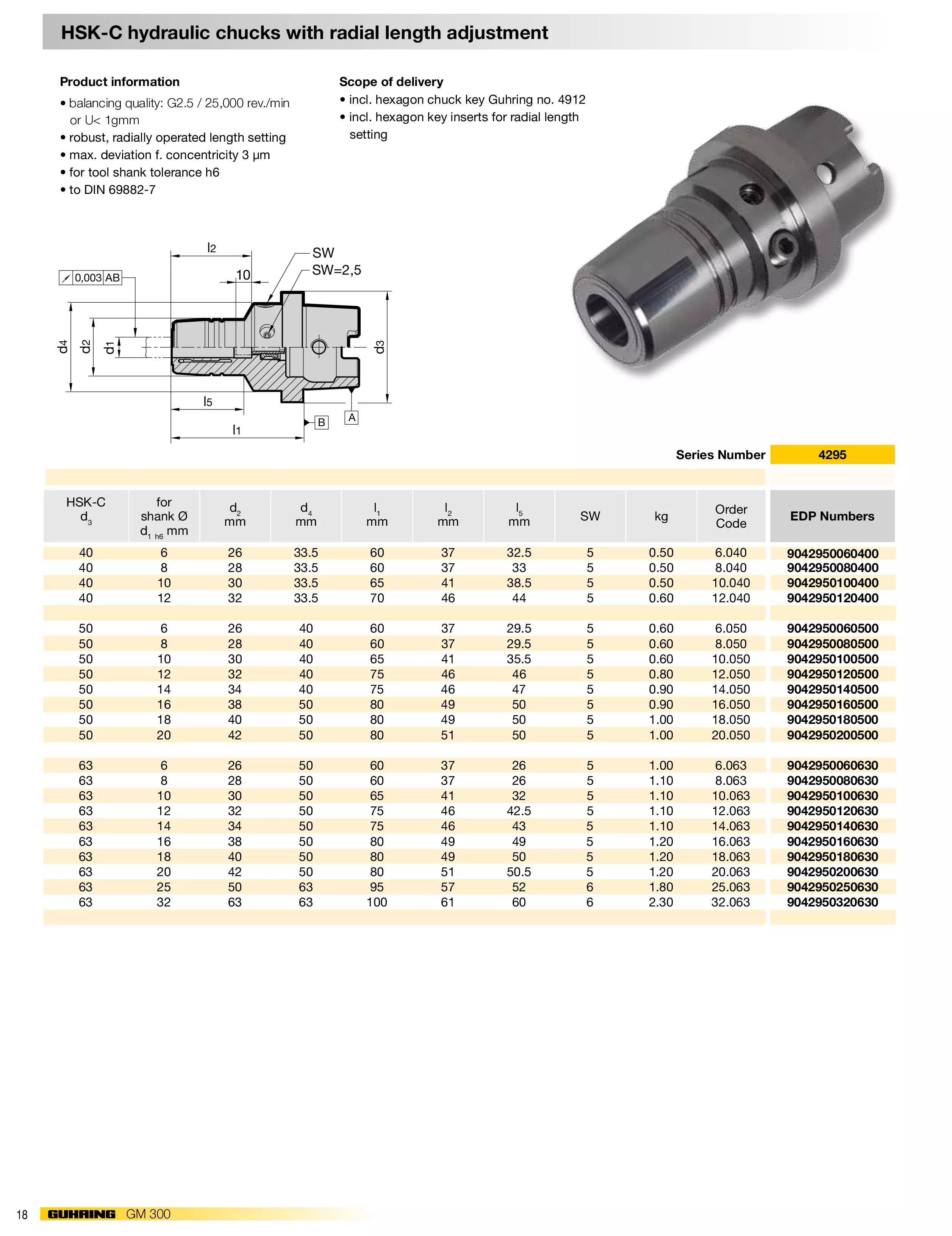
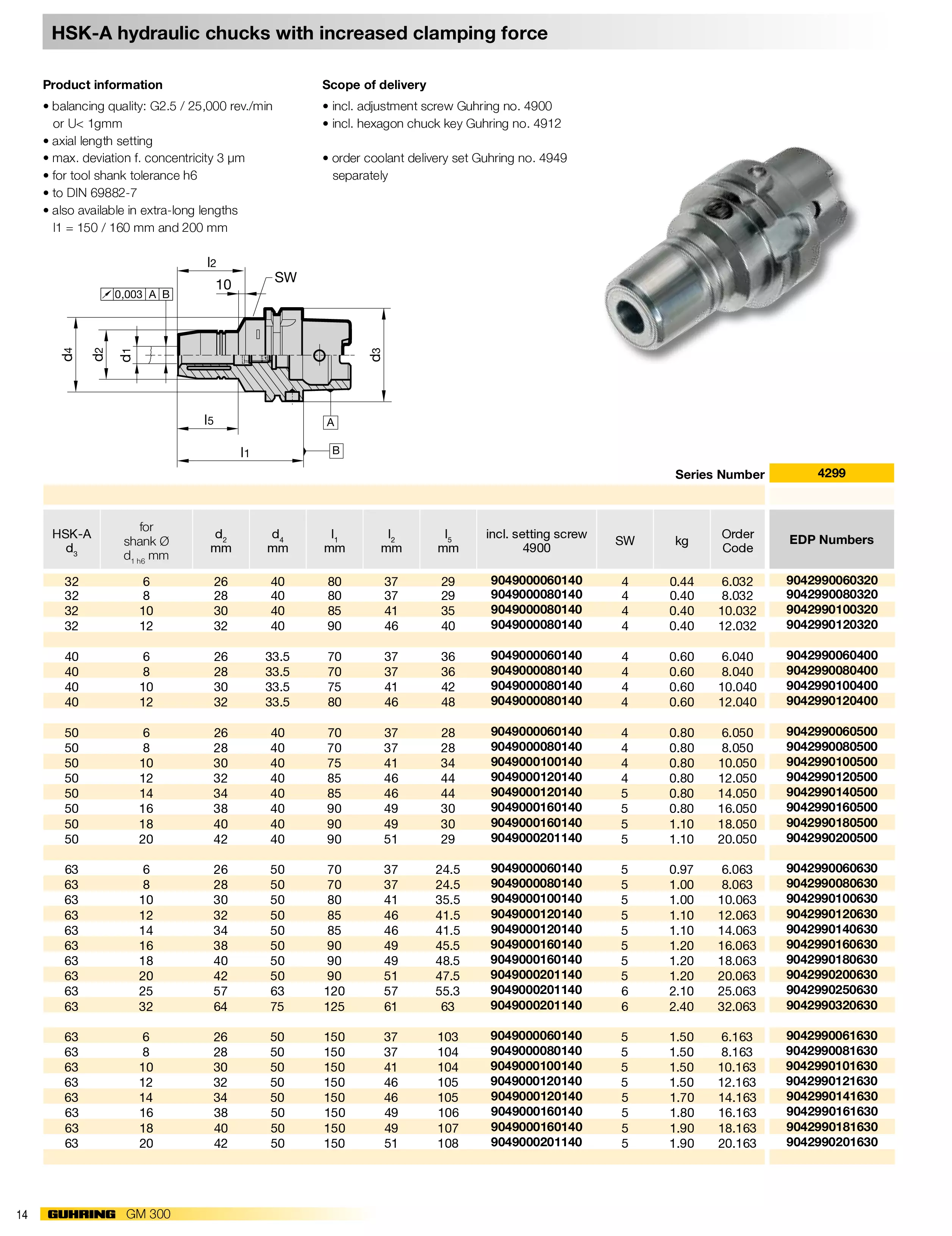
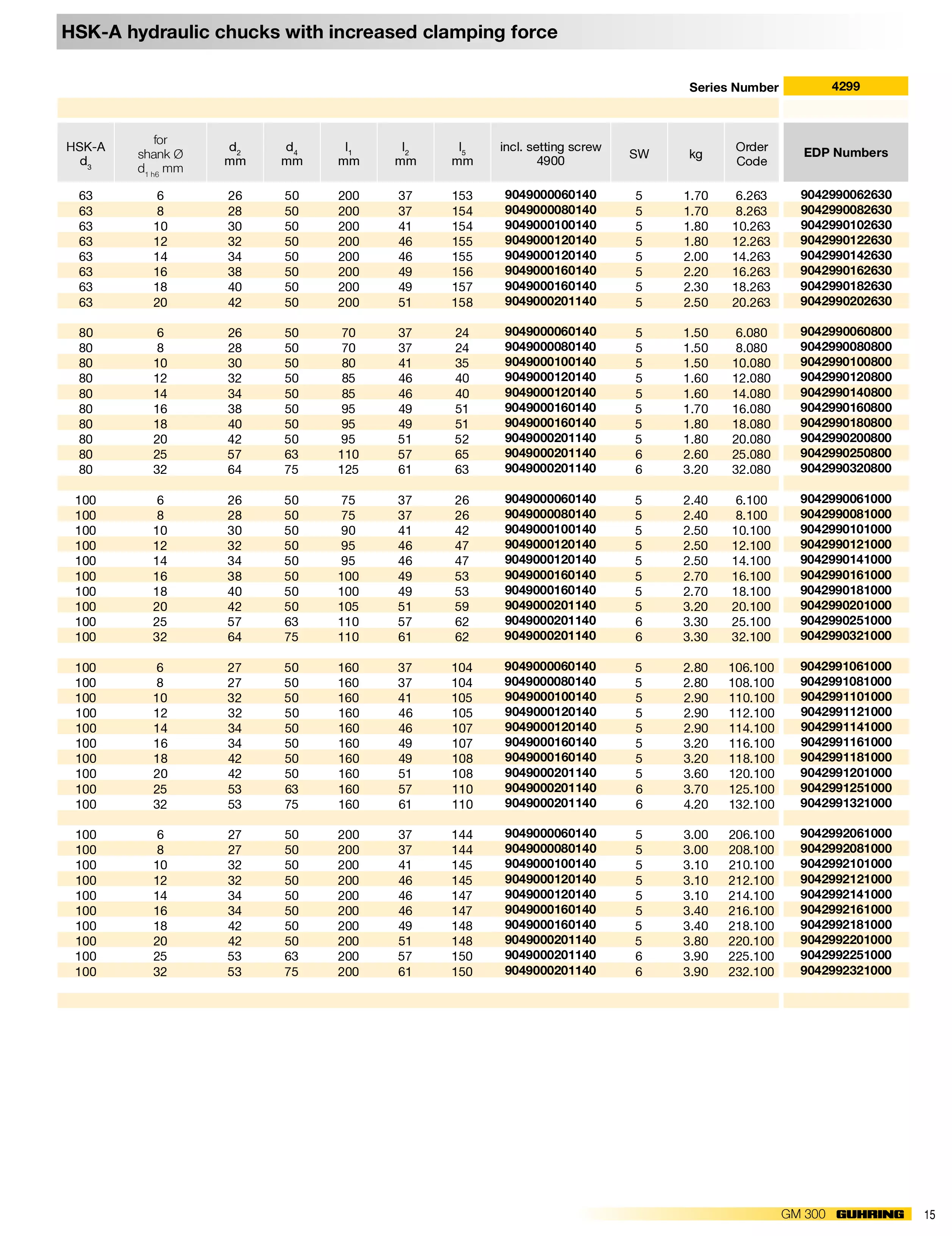
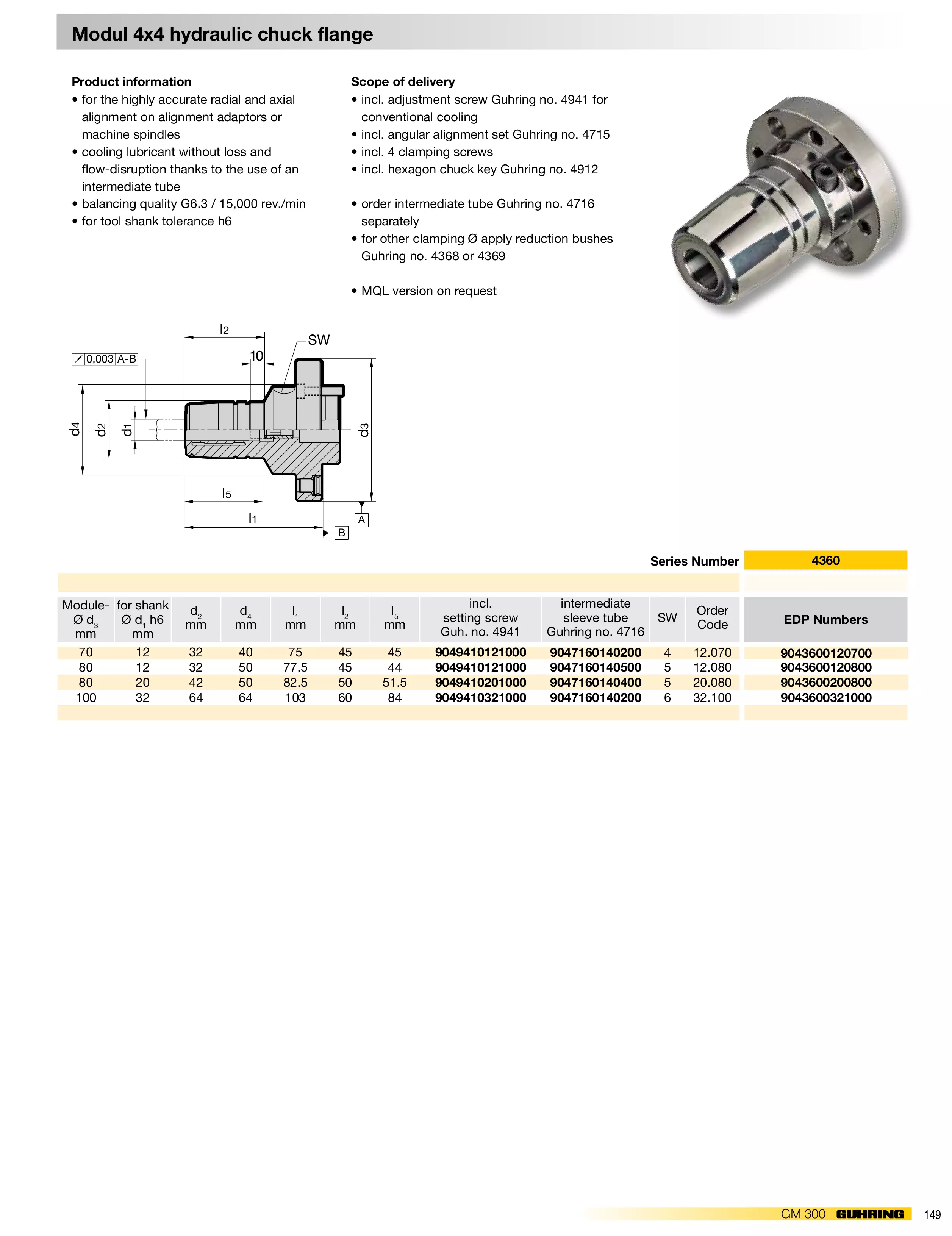
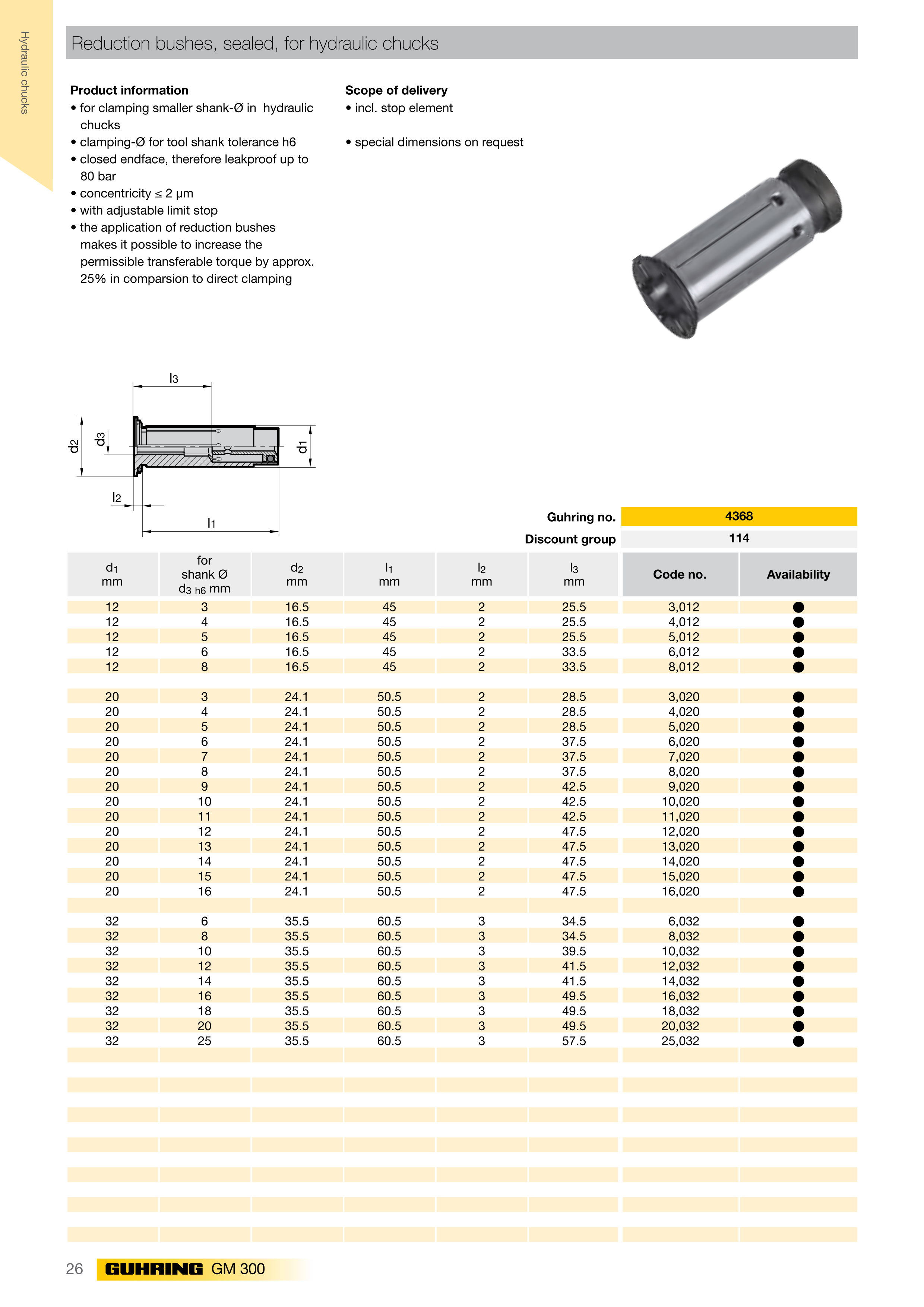
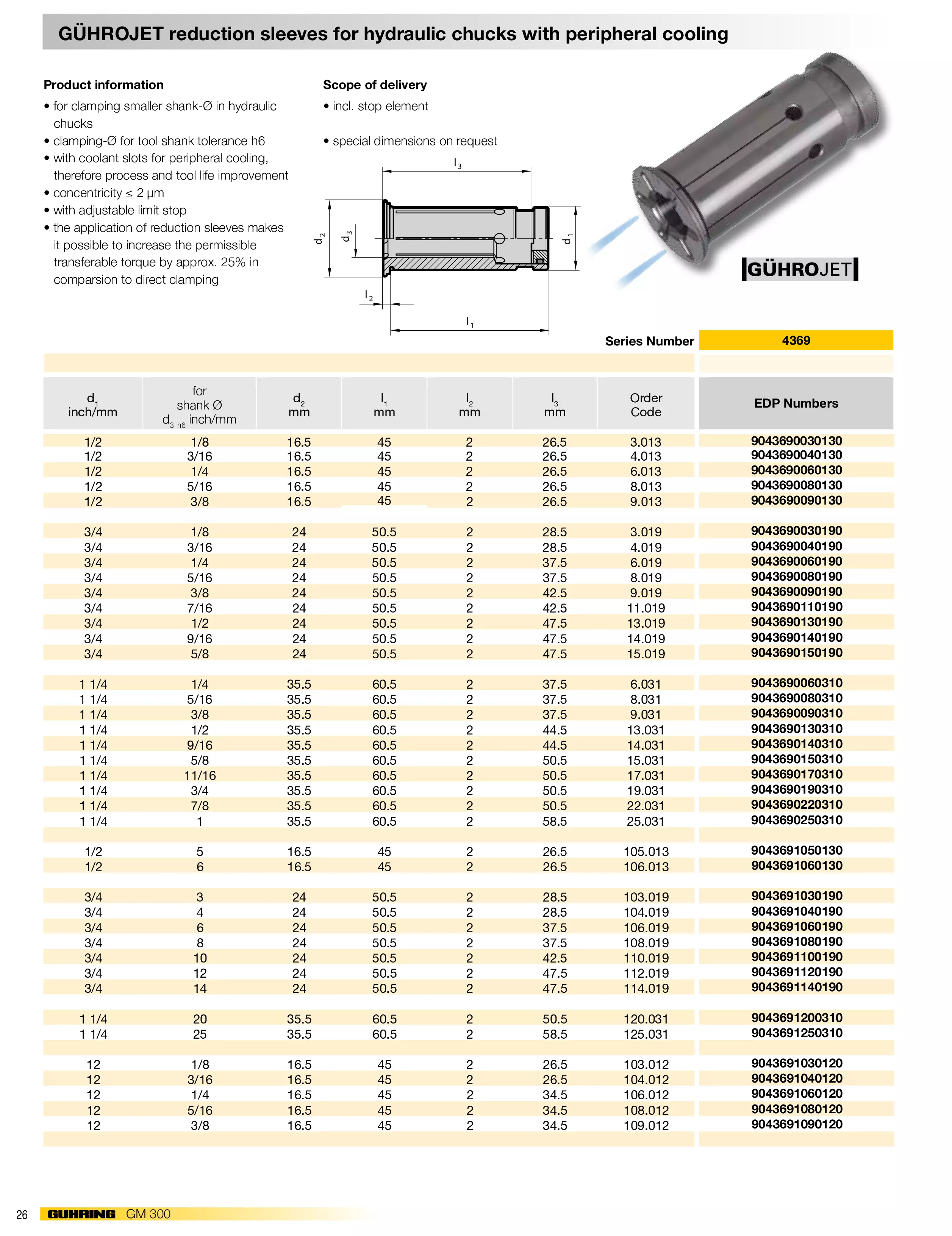
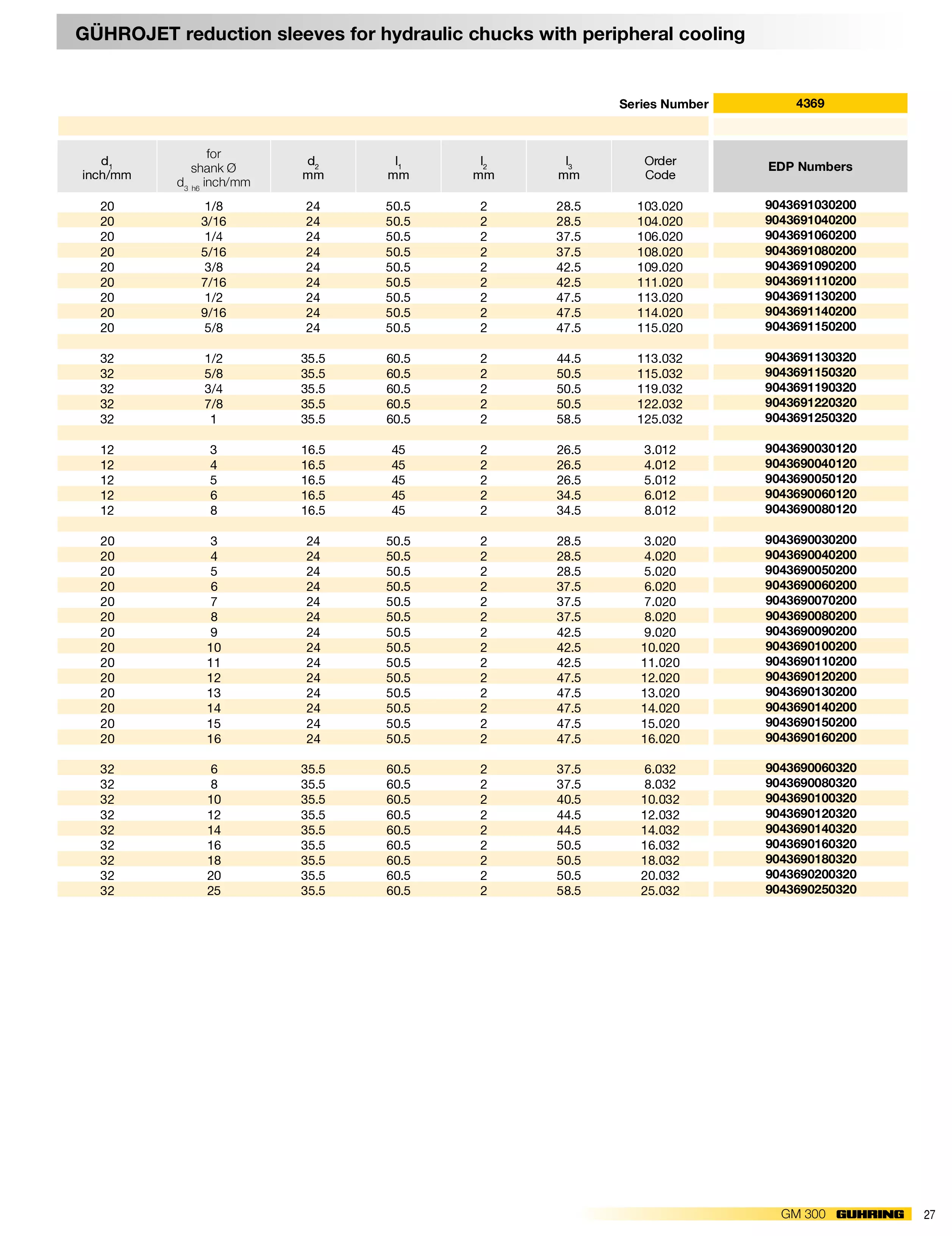
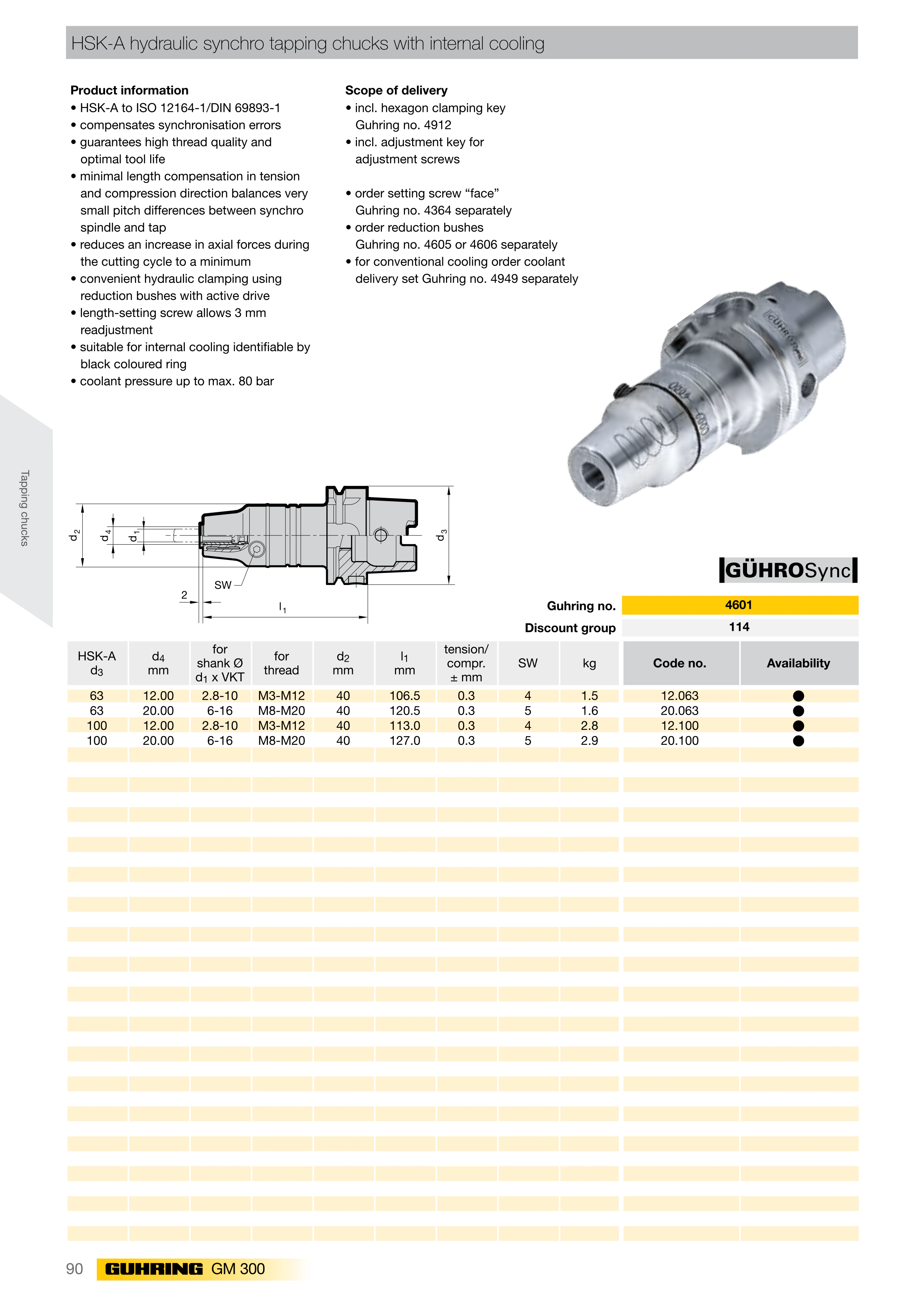
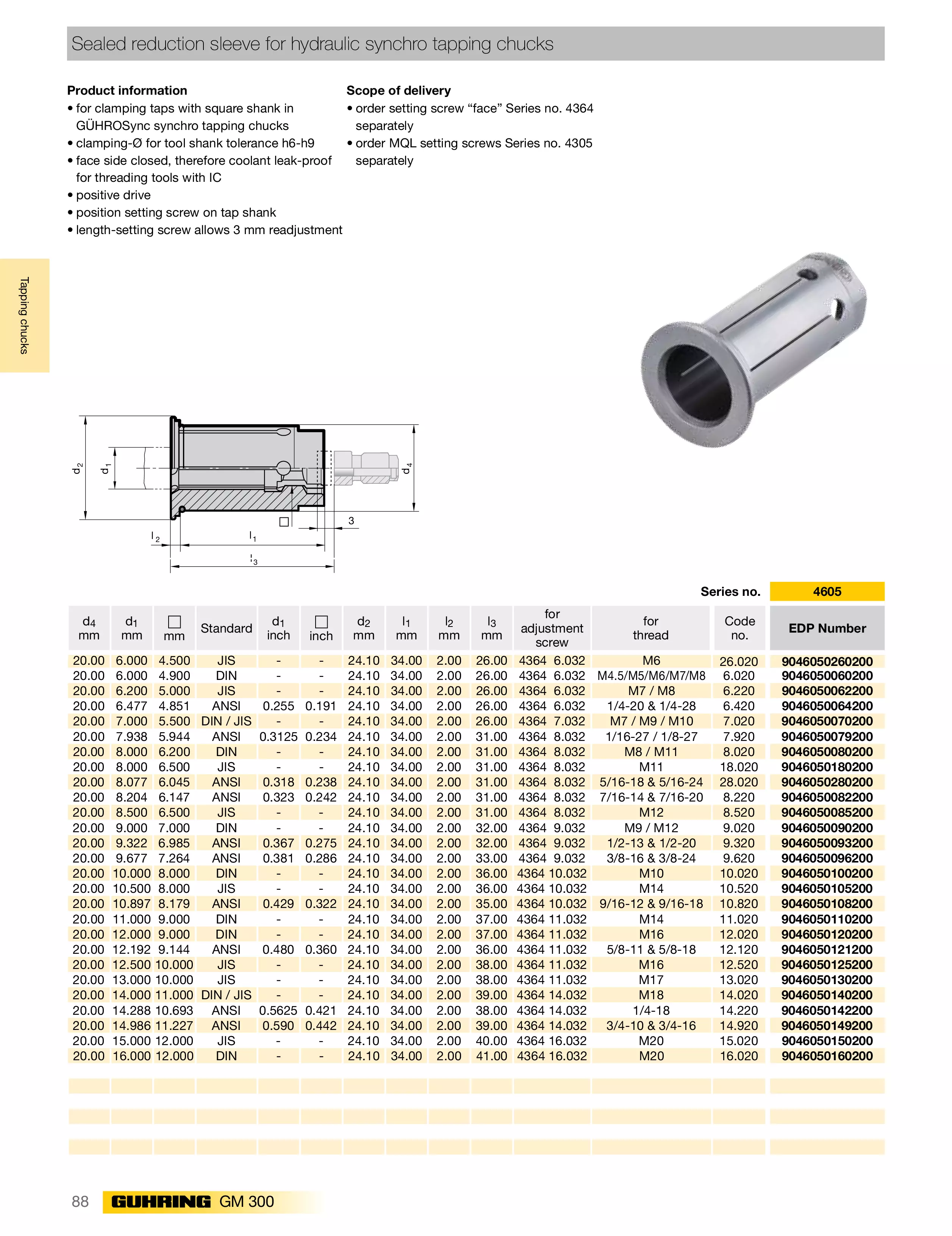
Dos-执行多命令
“&” 的使用方法(最推荐大家使用它了,容错率最好)
1 | command 1 & command 2 & command 3...... |
可以同时执行多条命令,即使这3个命令中有任何一个执行失败,其他任意2个命令都会执行成功。abcd命令是一个不存在的错误命令,就是显示下效果。如图所示:
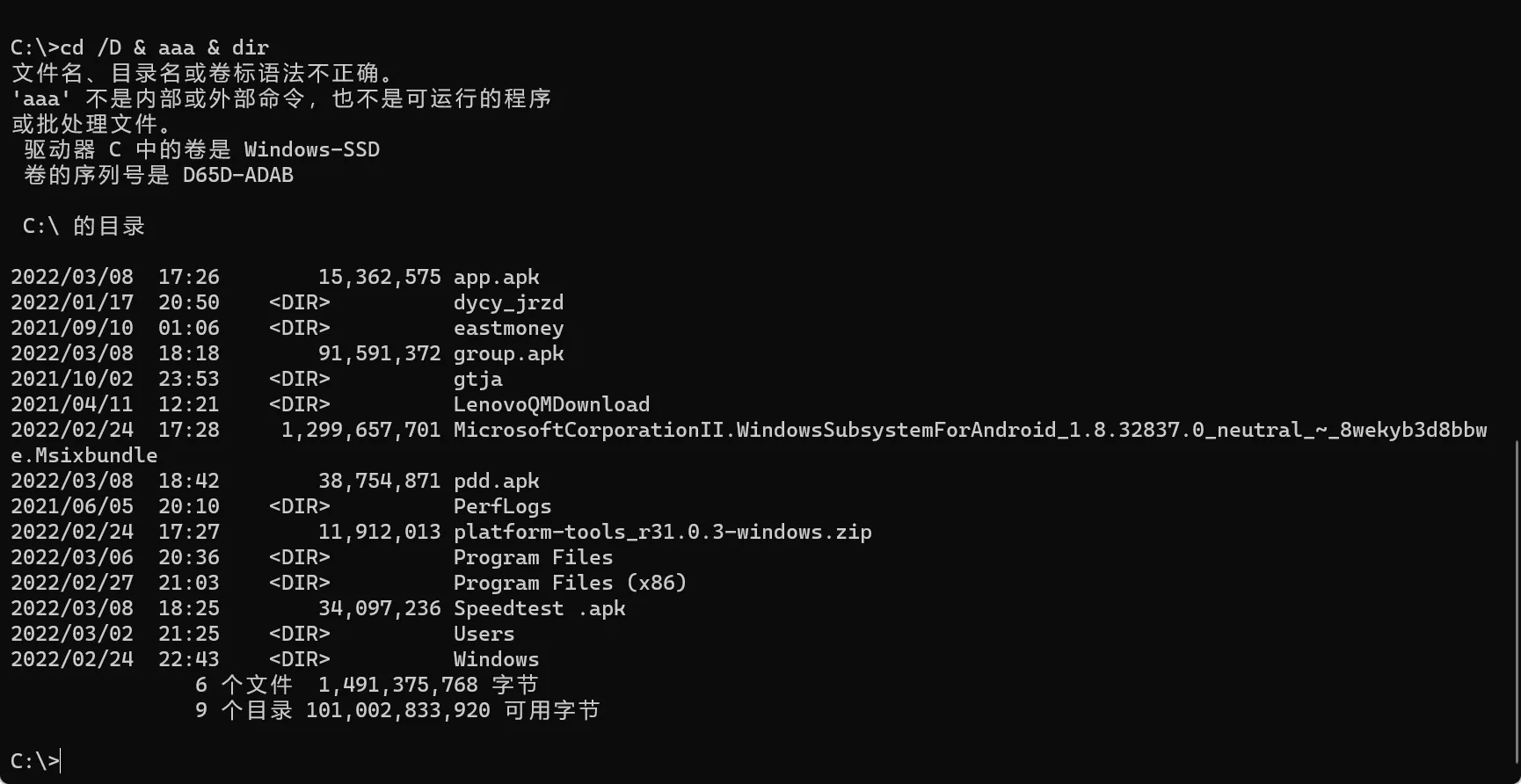
“&& “的使用方法
1 | command 1 && command 2 && command 3...... |
可以同时执行多条命令,如果这3个中有一处命令执行失败,那么当碰到执行失败的命令之后的其他任何命令都不会被执行。第一个calc命令会被正确执行,第二个abcd是不存在的错误命令,它执行失败后,第三个mspaint(画图程序)命令及之后的其他任何命令都不会被执行。如图:
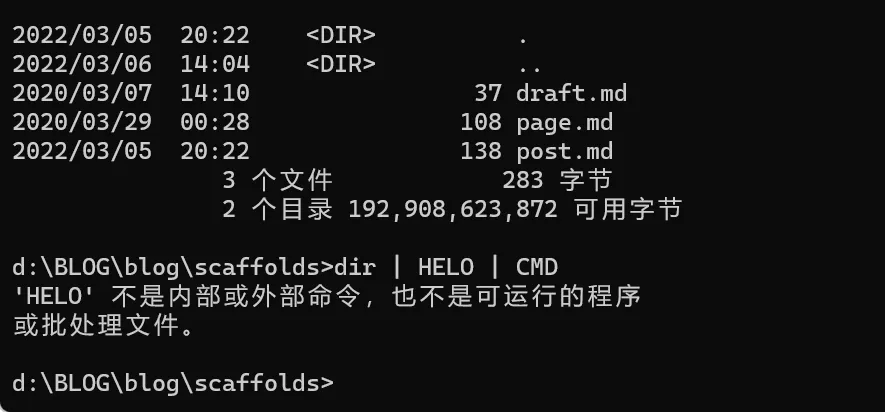
“|” 的使用方法(这个方法的使用意义最不大,容错率为0)
1 | command 1 | command 2 | command 3...... |
可以同时执行多条命令,这些命令中只要有一个错误的命令,不管是第几条命令,所有的命令都不会被执行。
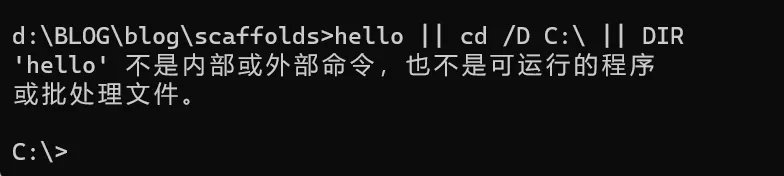
“||” 的使用方法
1 | command 1 || command 2 || command 3...... |
可以同时执行多条命令,无论有多少个命令并存,只要多条命令中有一个命令被正确执行,其他的任何命令都不会被执行。下图中第一条abcd是不存在的错误命令,但是第二条calc命令被正确执行,那么之后的mspaint命令不会再被执行,即使后面多条命令都是正确的。它只执行一条正确的命令。